Buffering and Batching AJAX Calls to Back-End API
At Zoosk, we maintain a single-page client app for web and Facebook applications, and handle our transactions with back-end servers using AJAX calls. One example of how this works is with Search—Instead of having a full-page reload each time someone wants to view the dating profile of a new candidate, the client just makes AJAX calls to the server, fetches the required data, and then dynamically creates the pages on the client side.
Our back-end API already supports batching calls. So, instead of issuing nine different AJAX calls to retrieve all the information required for displaying a candidate’s profile (e.g. photos, gifts list, compatibility scores, interests list, etc.), we make a single-batched HTTP request which wraps all these requests into one call. The biggest advantage to having one call rather than nine is that we eliminate redundancies in handshaking and establishing connections; which leads to less handling time from the user’s perspective and less load on our servers to handle inbound requests. As a very general rule of thumb, on average calls, we found that batching five calls (theoretically with the same average response time from the server of, say, 250 ms) takes as long as three individual calls.
Our Analytics and Data Science team logs and reports the number of single and batched API calls made by the clients to the API tier, as well as their average response time. Among the top frequent endpoints in the logs, quite expectedly, we found that the endpoint for “reporting a profile view” is always called as a single non-batched request. This call gets issued when a current user views another user’s dating profile and is fire-and-forget (reporting only), which means the client doesn’t need to wait for anything in the response. To simplify our calculations, let’s assume that 15% of the load from the Web client to the API layer was by this endpoint.
Buffer Single Calls Of Views
Knowing the benefits of batching, we thought that instead of making this call right after every single actual view, we could buffer the view jobs on the client side and issue them as batches every time they reached five views!
We had seen that a batch of five calls to the same endpoints takes the same amount of time as three single calls, so it could potentially save ~40% on the load on this endpoint which, theoretically, could result in ~5% less load from the Web client to the API tier.
Challenges and Solutions
Before running the experience, we addressed some of the challenges.
- Starvation
It might happen that a user views only four profiles and makes a long pause on the fourth profile to chat. So the fifth view would never happen and the batch call wouldn’t shape. To cover this, we added a timeout (30 seconds initially) for each call in the buffer. So if more than 30 seconds passed since the last job entered the buffer, and there’s at least one job there, we flush them all. The same flush happens if the user navigates away from the modules that create view jobs to other modules like SmartPick. - Delays in interactions
A buffer of size five and a timeout of 30 seconds could cause a view to an online user’s profile to get reported to the server with a delay of up to two minutes. This was a big concern because it could drop user engagement—because there were fewer chances for two online users to know they had mutually viewed each other in real-time. To cover this, we added some complexity and had multiple buffers based on the online status of the viewed users, with different sizes and timeouts. - Preserving cached jobs in buffer
Another question was how to handle the buffered, but not yet flushed, jobs if users lost their Internet connection, powered off their machines immediately, or closed their browsers. Up to four views could get lost. To cover this, we kept a synchronized backup copy of the buffer’s data in the LocalStorage space of users’ browsers. This way, even if users closed their browsers within 30 seconds of the last view, by the next time they got back to our website we could retrieve any unsent jobs and flush them immediately. Clearly this could cause some delays, but that was part of the price we were willing to pay for the 5% on load. Also, in order to cover this back up, we disabled the whole feature for users with old or incompatible browsers.
Result of the first experiment
We ran an experiment on a percentage of our users and monitored the performance of this mechanism, from both the server and client perspective, using various analytic tools. In addition to the before-mentioned challenges, we found that running QA tests over this complicated mechanism, as well as keeping it maintainable with multiple buffers, was a considerable cost. Also, the timeout threshold of up to 30 seconds (that could result in up to two minutes delay in client-side buffering before the flush) was enough to lose a noticeable amount of user engagement.
Carry the experience!
We learned a lot. We gave up on views and instead carried our knowledge to another endpoint. This time, we found that the endpoint that records responses to the Carousel feature was a suitable candidate. It was both a most frequently called endpoint and a fire-and-forget (reporting only) endpoint. Also, a good thing about the nature of the Carousel feature was that a timeout of five seconds could work fine, as most of our users who play Carousel usually respond to a Carousel candidate with Yes, No, or Maybe in less than five seconds. Also, we had a similar rule of thumb about saving and batching the Carousel calls. The chart below shows the Average Response Time (ART) for the batched Carousel calls versus single calls.
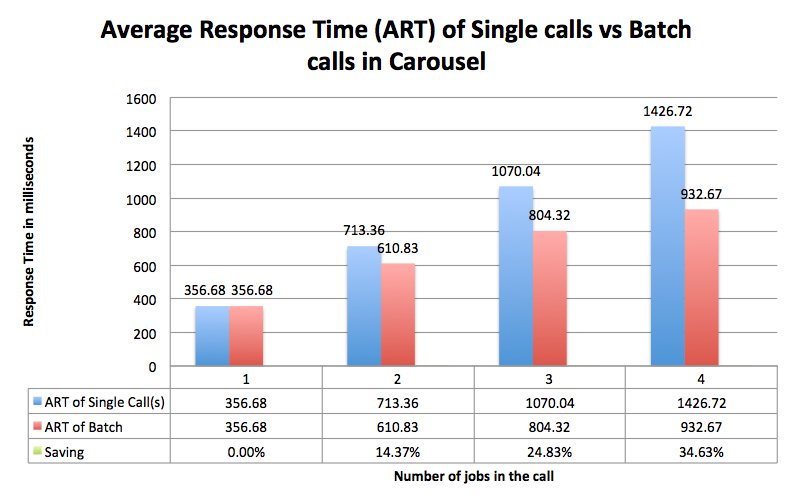
Our experiment on Carousel was very successful! We experienced almost no loss in user engagement and a total savings of more than 30% on this endpoint’s load, with no cost to the user.
Sharing it with other teams
In “how-to-explain-it-to-your-grandmother” language, what the mechanism does is this: Instead of making single calls every time a user says Yes or No to a candidate, the grandmother, who is a good listener, memorizes the answers and makes a phone call to the server, either when she can’t memorize anymore (because the buffer gets full with four responses) or when a user pauses for a long breath (when a job gets timed out). In her phone call the grandmother says that the current user likes this and this, and doesn’t like that and that. One phone call only!
This idea was very successful with our Web client team so we passed it on to the other client teams at Zoosk. Our iOS team, whose great efforts have helped make Zoosk’s app the #1 grossing online dating app in the Apple App Store, ran a similar experience on prefetching and buffering profile data in the Search feature and saved more than 6% in total on their load to the API layer!
We plan to have our other client teams (Android and Touch) implement this optimization as well.
Thanks
Carrying a purely algorithmic background, I was hesitant to pursue my career in front-end development, which is stereo-typically known for trying to have JavaScript and HTML code work well in all browsers, including Internet Explorer! But today I want to thank the engineering team at Zoosk, who gave me this opportunity to propose, develop, and run various experiments on this idea, learn a lot from end-to-end, and finally have this project help tens of millions of users everyday.